Включение в план поддерживающих буферов
Для большинства команд в большинстве ситуаций скользящий опережающий план вполне уместен. Однако бывает, что взаимодействия команд настолько сложны или часты, что простого скользящего опережающего планирования, описанного в предыдущем разделе, недостаточно. В таких случаях первое, что нужно сделать, это попытаться сократить количество взаимодействий до уровня, при котором скользящее опережающее планирование станет реальным. Если добиться этого не удается, попробуйте включить в итерацию поддерживающий буфер, который даст свободу, необходимую другим командам. Поддерживающий буфер, как и временной буфер, описанный в предыдущей главе, защищает своевременную поставку набора новых возможностей. Это довольно сложный способ сказать простую вещь: если вашей команде требуется что-либо от моей команды к 8:00, то моей команде не следует планировать завершение этого на 7:59. Иначе говоря, нам нужен план вроде того, что представлен на рис. 18.2.
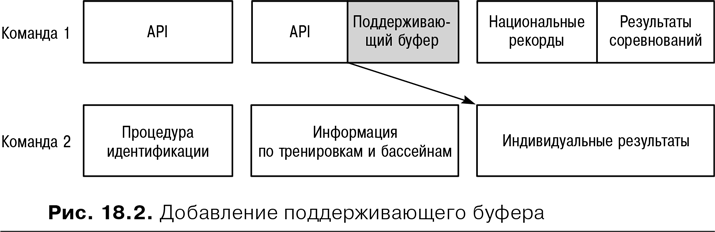
На рис. 18.2 поддерживающий буфер вставлен между завершением API командой 1 и началом работы команды 2 с использованием API над пользовательской историей, связанной с данными по индивидуальным результатам. Поддерживающий буфер защищает дату начала работы над историей, связанной с данными по индивидуальным результатам, от задержек в реализации API.
Чтобы включить поддерживающий буфер в план релиза, нужно всего лишь временно планировать работу с расчетом на более низкую скорость команды, которая поставляет определенную возможность другой команде. В случае, представленном на рис. 18.2, усилия команды 1 равномерно делятся между завершением API и поддерживающим буфером так, чтобы гарантировать команде 2 возможность приступить к работе над индивидуальными результатами с самого начала третьей итерации. Это не означает, что команда 1 получает возможность не торопиться в процессе второй итерации. В действительности от нее ожидают, что она выполнит связанную с API работу в 10 пунктов, использует только часть буфера и начнет работать над пользовательской историей, связанной с национальными рекордами, уже во второй итерации.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК